Baca Panduan Lengkap Ini agar Paham Fungsi Robots.txt untuk SEO
Ditulis oleh : Humaira Aliya
Bicara soal optimasi website, robots.txt adalah salah satu file yang harus diperhatikan penggunaannya.
Pasalnya, robots.txt ini merupakan semacam portal yang memungkinkan search engine untuk mengakses konten di situsmu.
Kalau salah, bisa jadi konten penting yang ada di website justru tak terindeks dan tidak muncul di halaman hasil pencarian.
Siapa pun yang menjalankan search engine optimization (SEO) pasti tidak menginginkan hal tersebut.
Maka dari itu, penting bagimu untuk mempelajari apa itu robots.txt, cara menggunakannya, dan juga perbedaannya dengan salah satu komponen SEO lainnya.
Yuk, simak sampai tuntas!
Isi Artikel
Apa Itu Robots.txt?
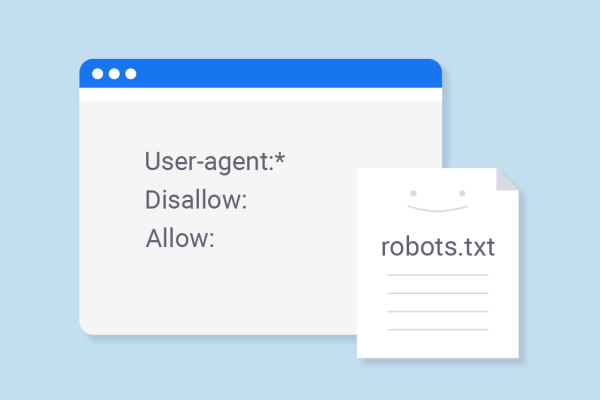
© Sitechecker.com
Sebelum masuk lebih dalam, Glints akan menjelaskan terlebih dahulu mengenai apa itu robots.txt.
Sebenarnya, sudah ada sedikit bocoran dari namanya. “Robots” dan “txt” (text). Jadi, jelas kaitannya antara teks dan juga robot.
Akan tetapi, robot apa yang dimaksud?
Dikutip dari MOZ, robots.txt adalah sebuah kode atau file yang digunakan untuk memberi instruksi pada robot search engine.
Instruksi tersebut adalah untuk menjalankan web crawling menggunakan spider, agar situs dan URL yang ada di dalamnya dapat terindeks.
Di awal sudah sempat disebutkan bahwa kalau tidak terdeteksi dan terindeks oleh crawler, situs atau konten yang dibuat tidak akan muncul di halaman hasil pencarian search engine.
MOZ juga menyebutkan bahwa robots.txt akan menentukan software web crawling (user agent) mana saja yang dapat menelusuri sebuah website.
Contoh
Menurut Google Search Central, robots.txt berada di dalam root situsmu.
Misalnya, situs www.example.com, file robots.txt berada di www.example.com/robots.txt.
Untuk penggunaan robots.txt itu sendiri, berikut ini adalah salah satu contohnya.
(1)
User-agent: Googlebot
Disallow: /nogooglebot/
(2)
User-agent: *
Allow: /
Dari contoh tersebut, terlihat jelas bahwa contoh (1) terdapat website yang tidak memberi izin Googlebot untuk crawling di situsnya.
Pada contoh kedua, dapat dilihat bahwa user-agent lainnya bisa mengakses situs tersebut, ditandai dengan simbol (*) setelah tulisan user-agent.
Penggunaan robots.txt ini nantinya bisa diutak-atik, sesuai dengan konten yang ingin diatur.
Apakah Kamu Membutuhkannya?

© Freepik.com
Setelah membaca pengertian dan contohnya, mungkin sekarang kamu bertanya-tanya, “Butuh menggunakan robots.txt untuk website saya tidak, ya?”.
Sebenarnya, website kecil tak terlalu membutuhkan robots.txt. Akan tetapi, bukan berarti tidak boleh pakai sama sekali, ya.
Disarikan dari Ahrefs, berikut ini adalah manfaat robots.txt jika kamu memutuskan untuk menggunakannya:
- mencegah crawling di konten duplikat
- meringankan beban server
- memastikan ada bagian dari website yang sepenuhnya private untuk tes dan pengaturan
- mencegah muncul gambar atau video di hasil pencarian Google (di kategori “All”, bukan “Images”)
Kalau ingin meringankan beban dan merasakan manfaat yang disebutkan, kamu bisa menggunakan robots.txt untuk optimasi situsmu.
Backlinko juga menjelaskan, kalau memang jumlah halaman terindeks sudah sesuai dengan yang diinginkan, tak perlu lagi menggunakan robots.txt.
Kamu bisa mengecek angka tersebut menggunakan Google Search Console, untuk tahu jumlah halaman terindeks, apakah ada eror atau tidak, dan mana saja yang sengaja tidak diindeks.
Tampilannya kurang lebih seperti ini:
Robots.txt vs. Meta Tag

© Unsplash.com
Kalau kamu sudah cukup familier dengan search engine optimization (SEO), perlu diingat bahwa robots.txt dan meta tag adalah dua hal yang berbeda.
Memang, sekilas terlihat bahwa fungsinya sama-sama saja, yaitu memberi tahu search engine konten mana yang bisa di-crawl dan mana yang tidak (contoh: “noindex”, “follow”, “nofollow” pada meta tag).
Akan tetapi, kedua komponen penting dalam SEO ini memiliki perbedaan yang cukup mendasar.
Menurut Search Engine Journal, robots.txt digunakan untuk memberi instruksi kepada web crawlers seputar seluruh situs, sedangkan meta tag hanya fokus untuk satu halaman spesifik.
Jadi, penggunaannya pun harus disesuaikan dengan kebutuhan situs itu sendiri. Jangan sampai tertukar, ya.
Dari artikel ini, dapat disimpulkan bahwa robots.txt adalah file atau komponen website yang bisa berdampak baik pada praktik SEO.
Perlu diingat bahwa penggunaan elemen ini tak selalu 100% berhasil, ya.
Pasalnya, kalau memang ada satu link yang mengarah ke satu halaman dengan larangan untuk crawling dan halaman yang mengarahkannya terindeks, bisa saja halaman tersebut tetap ada di hasil pencarian.
Jika kamu masih haus ilmu dan ingin memperluas pengetahuan seputar marketing, tenang saja. Ada Glints ExpertClass yang siap penuhi kebutuhanmu.
Glints ExpertClass adalah kelas yang akan dibawakan oleh para profesional marketing, dengan bertahun-tahun pengalaman yang tak perlu diragukan.
Jadi, tunggu apa lagi? Cari kelas yang ingin diikuti dan daftarkan dirimu, sekarang juga!